Before You Buy the Graph Database: Start Building Architecture.
How two Helsinki tickets, one podcast rabbit hole, and a series on Knowledge Graph Architecture ruined my weekend — in the best way possible.

It started with two tickets. Helsinki Data Week 2026 - with Jessica Talisman as a speaker at the Opening Event. Anyone familiar with Jessica’s work knows her take on Knowledge Engineering is anything but abstract: it’s hands-on architecture you can put into practice right away.
Browsing the program, I spotted a familiar name among the organizers: Säde Haveri. I know Säde from the Knowledge Graph Academy, where we studied the foundations of semantic systems together - learning from Katariina Kari, Tony Seale, and Jessica Talisman. That led me to the Helsinki Data Mafia Podcast “Towards HDW2026!”, where Säde and Juha Korpela dive deep into semantics, knowledge graphs, and conceptual data modelling in the enterprise. Their core argument hits a nerve: organizations pour millions into graph databases and AI platforms - but few do the homework that actually makes AI and knowledge graphs deliver value: building the controlled vocabularies, taxonomies, ontologies, and semantic governance underneath.
Almost simultaneously, Jessica published the first article of a new series on exactly this topic:

Which components are essential? What’s optional but strategic? And why is the semantic layer not a nice-to-have but the actual competitive advantage?
Sometimes a circle closes in ways you can’t plan. A podcast, an article, a shared learning journey - all pointing at the same truth: if you’re serious about knowledge graphs, start with the architecture, not the tool.
That’s what this article is about.
The Blind Spot: Containers Without Content
The knowledge graph tool market is booming. Neo4j, Snowflake semantic views, Cube, data catalogs with MCP integrations. Vendors are racing to position their products as the container for an organization’s semantic future. But a familiar pattern keeps repeating.
Säde Haveri puts it plainly in the Podcast:
“I see all of these [data catalogs, Cube, Snowflake semantic views, Neo4j knowledge graph tools] as containers of the metadata. And I’m afraid that we are again focusing on which tool to purchase, when we should first be focusing on that we actually have the content, the models, the understanding that we’re going to put into the tool.”
— Säde Haveri
Juha Korpela sharpens the point:
“We focus on the place in which we put things more than the things that we are going to be putting there.”
— Juha Korpela
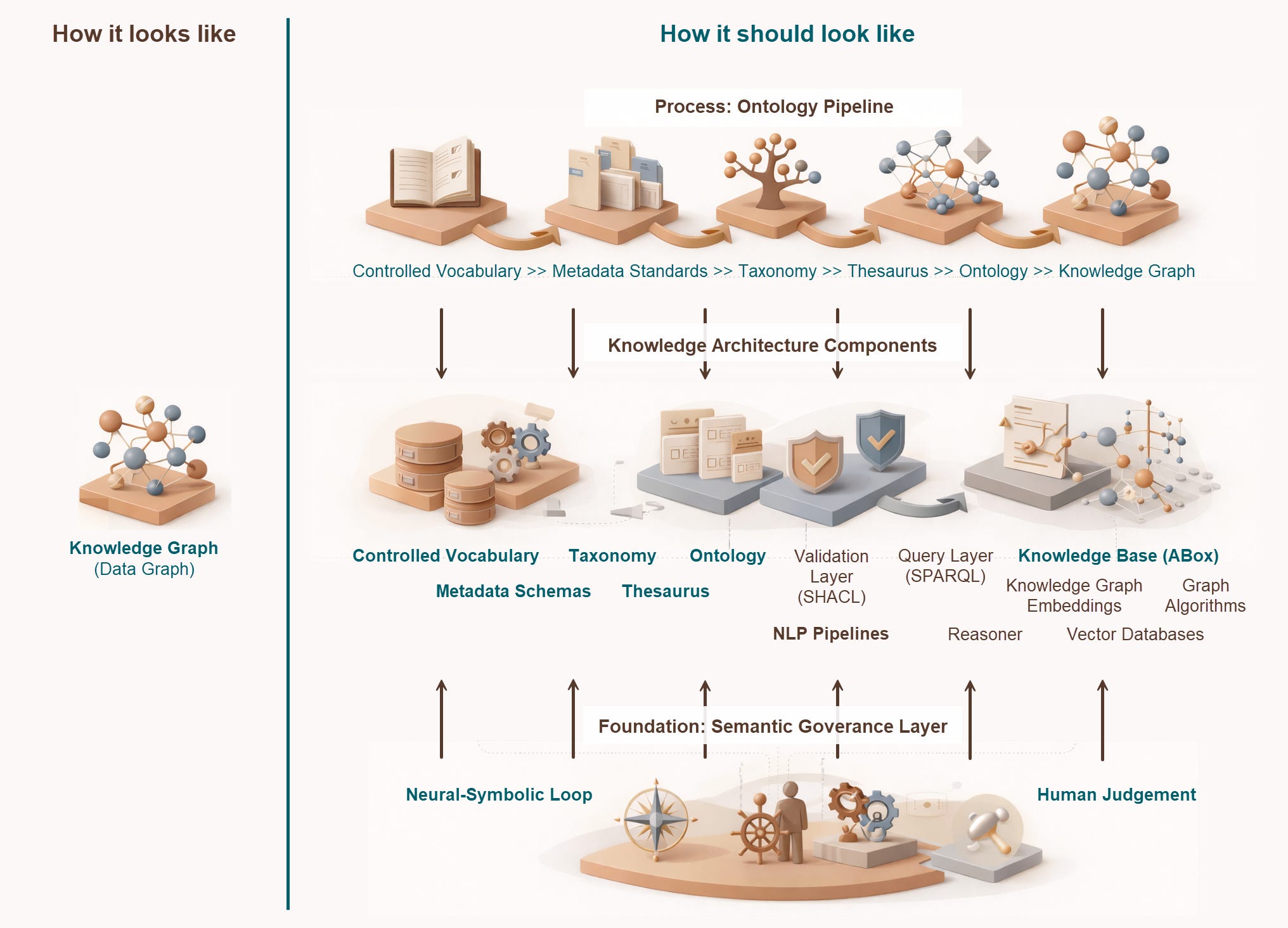
Left: what most organizations build. Right: what a knowledge graph actually needs. The gap between the two is the architecture nobody wants to do - and the only part that matters.
(Illustration by the author based on Jessica Talisman’s Ontology Pipeline and Knowledge Graphs Architecture Part 1, created with AI assistance.)
So what, exactly, are the things that should go in there? Jessica Talisman’s architecture framework lays it out with remarkable clarity. The components fall into three tiers: those you absolutely need, those that support production-grade systems, and those you adopt based on your domain and ambitions. All of them are organized along the Ontology Pipeline - a sequential, iterative process framework where each stage prepares the foundation for the next.
Let’s walk through them. Not as an abstract checklist, but as a story of what breaks when you skip a stage.
The Required Architecture: Five Components You Cannot Skip

Controlled Vocabulary - Getting Your Language Straight
Every knowledge graph starts here. A controlled vocabulary is a curated, disambiguated list of canonical terms and definitions for your domain. It works hand in hand with data cleaning - deduplication, synonym resolution, normalization. Its job is deceptively simple: make sure that everyone, human and machine, uses the same terms with the same meaning.
Skip this step, and you load undefined, duplicated, synonymous terms into your shiny new graph tool and call it semantics. You haven’t built a knowledge graph. You’ve built an expensive mess with a graph data structure.
Taxonomy - Giving Your Concepts a Backbone
Once the vocabulary is clean, terms need structure. A taxonomy organizes concepts into broader-to-narrower hierarchies - “this thing is a kind of that thing” - typically encoded in SKOS. It provides navigational logic, supports tagging and annotation, and gives machine learning classification tasks something to classify into.
Without a taxonomy, your terms sit in a flat, unstructured pool. Search is guesswork. Classification is ad hoc. And the next stage - the thesaurus - has nothing to build on.
Thesaurus - Handling the Ambiguity
Language is messy. The same concept goes by different names. Different concepts share the same name. The thesaurus extends the taxonomy by adding associative relationships: broader terms, narrower terms, synonyms, related terms. Encoded in SKOS, it is the layer that handles ambiguity by forming cross-hierarchical connections between concepts.
This is where something crucial happens: the thesaurus establishes semantic reasoning at a primitive level. It is the first step toward a fully ontology-based system - the bridge between “we organized our terms” and “machines can start reasoning about them.”
Ontology - The Formal Logic of Your Domain
The ontology is the formal logical model, expressed in OWL 2. Classes, properties, axioms, cardinality restrictions, disjointness constraints, logical rules - this is the component that enables machines to derive new facts from existing ones, detect inconsistencies, and enforce formal constraints on what may be asserted.
Without an ontology, a graph database is just a database that happens to use a graph data structure. With one, machines can reason. That distinction is everything.
Juha Korpela makes the architectural point explicit in the Podcast when he describes what happens when vendors offer semantic tooling without this foundation:
“When a vendor says ‘this is where you can put your data products,’ people take it to mean that whenever I put something there, it becomes a data product. And now it’s the same with metadata, the same with semantics. So OK, the vendor says ‘this is where you can have your semantic models’ and people put anything there and they think that this is now semantic information and a semantic layer.”
— Juha Korpela
The result is what Juha calls semantic silos - isolated pockets of partially described data in individual tools, none of which connect to a coherent knowledge layer. As he puts it:
“Semantics is by its nature something that is technology agnostic. It is a question of what things mean. It’s not a question of, you know, what attributes we have in this table or whatever. And I don’t think that the meaning and the technical implementation can or should live in the same place.”
— Juha Korpela
Knowledge Base - Where Facts Live
The knowledge base is the store of asserted facts - the instance data that populates the ontology’s logical model. In RDF architectures, this is a triple store; in property graph architectures, a labeled property graph database. It stores the entities and relationships that the ontology makes it possible to reason over.
In Talisman’s framework, the knowledge base is the ABox - the assertional box. It is absolutely necessary. But it is one of at minimum five required components, not the whole architecture. When organizations buy a graph database and start loading data, they are addressing exactly this one layer and nothing else.
Without the vocabulary, taxonomy, thesaurus, and ontology underneath, the knowledge base is - to borrow Jessica’s phrase - a graph of facts with no formal model.
The Infrastructure Underneath: Metadata Schemas
There is a sixth component that is essential in any production-grade system: metadata schemas.
Metadata captures context. Who asserted this fact? When? From which source? Under what authority? Under what license? Standards like Dublin Core, DCAT, PROV-O, and Schema.org provide the infrastructure of provenance and description that grounds every entity in the knowledge graph.
Without metadata, assertions in the graph are floating claims - technically present, but with no way to trace, verify, or trust them. In a world where AI systems consume and act on knowledge graph data, that lack of grounding is not a gap. It’s a liability.
Why Your Competitive Advantage Must Not Be in the LLM
So far, this has been an argument about engineering discipline. But there’s a deeper, strategic reason why organizations cannot afford to shortcut the architecture. It concerns what makes a business unique - and what happens when that uniqueness evaporates.
Säde Haveri frames it as a test:
“Anything that you consider your competitive advantage as a company - you should hope that the general models, GPT, Claude, Gemini, are not very good in this area, because otherwise that’s maybe slightly dangerous.”
— Säde Haveri
She returns to this argument later with striking clarity:
“If the LLM can answer any of your core business advantage things, then maybe your business is not very good.”
— Säde Haveri
Juha Korpela extends this into a prediction about what’s coming:
“The competitive advantage is in the uniqueness of your organization. If the LLM is able to output everything that you do perfectly, then where is your advantage? You have none. [...] We’re going to be seeing companies going under because it will become apparent that there are companies that actually do not have a lot of advantage. Much of what they do is just repeating stuff that everyone else does as well, but they have been safe for a little while because they are hidden behind the obscurities of some obscure industry. But now the generic stuff - AI can do that in any industry soon.”
— Juha Korpela
This connects directly to the architecture. If an organization’s value lies in its unique domain knowledge - its specific definitions, its particular process flows, its proprietary classifications and relationships - then that knowledge must be captured, formalized, and made available to AI through the very components that tool-centric approaches skip.
The controlled vocabulary captures how your organization names things, resolves your synonyms, defines your canonical terms. The ontology formalizes your domain logic. The knowledge base, populated through your ontology, stores the asserted facts that are unique to your domain. None of this can be generated by an LLM, because the LLM’s training data contains the generic, not the specific. As Juha explains:
“The actual value in this whole thing is the tacit knowledge that is specific to your organization. The agents can only create information that they already have in the training data set, so whatever you get out of an LLM is going to be generic. [...] You can probably deal with some basics - OK, ‘a car is a vehicle’ type of ontology, you can get that out of an LLM, no problem. But you cannot get the information that is specific to your organization, which is the most valuable information there is, because you’re going to be needing precisely that for your agents to make them actually valuable.”
— Juha Korpela
And here’s the trap. When organizations try to shortcut this work by having AI generate the semantic layer itself, they end up in what Juha calls a fake thinking loop:
“There’s a fake thinking loop going on: ‘I need context for my agents, but I don’t want to deal with the context, so I’m just going to have an agent generate the context.’ And now there’s context being generated by agents, being read by agents. That’s not going to make anyone any smarter whatsoever.”
— Juha Korpela
The alternative is the architecture. Each stage of the Ontology Pipeline - vocabulary, taxonomy, thesaurus, ontology, knowledge base - forces the organization to extract and encode its tacit knowledge into structures that machines can reason over. Knowledge that no foundation model possesses. Knowledge that no amount of prompt engineering can substitute.
The Semantic Governance Layer: Keeping Humans in Control

This brings us to a component (as an extension of the architectural components) that cuts across the entire architecture: the Semantic Governance Layer.
One of the recurring lessons throughout the Knowledge Graph Academy - and in particular the lesson with Tony Seale on the Neural-Symbolic Loop - was that humans must remain in control of how knowledge is structured, defined, and documented. No LLM can do this on its own. It simply lacks the contextual understanding of a specific business, its domain logic, its organizational decisions, and the reasons behind them. That knowledge lives with the people who built the business and operate within it every day.
Säde and Juha made the same point in their Podcast: without human governance over the semantic layer, organizations lose the ability to steer, audit, and correct the knowledge systems that increasingly drive their operations.
The Semantic Governance Layer is not a single technology. It is the composite function that vocabulary, ontology, and validation serve together - the interface between human understanding and machine intelligence. In the neurosymbolic paradigm, the ontology provides the symbolic, the LLM provides the neural. The Semantic Governance Layer is what keeps the symbolic side under human control.
When the Architecture Is in Place: The Optional Powerhouse
Here’s where it gets exciting. Once the required components are solid, a range of optional capabilities becomes available - each one powerful precisely because it has a proper semantic foundation to operate on.
Again, consider this the appetizer - Jessica Talisman's series on Knowledge Graph Architecture is the full course ...
Reasoner - A software component that applies the ontology’s formal axioms to derive new facts from existing assertions. Automated inference: deriving implicit truths from explicit ones. An individual gets automatically classified based on relationship axioms, without anyone having to assert it manually. The reasoner needs the ontology to reason. Without it, there’s nothing to infer from.
Validation Layer (SHACL) - The W3C standard for defining and enforcing constraints over RDF graph data. Operating under closed-world assumptions, SHACL acts as the quality gate: enforcing required properties, expected datatypes, and relationship targets. It catches data quality failures before they propagate downstream. Think of it as the immune system of your knowledge graph.
Query Layer (SPARQL) - The W3C standard query language for RDF-based knowledge graphs. SELECT, CONSTRUCT, ASK, DESCRIBE, federated queries across remote endpoints - SPARQL is the operational interface through which vocabulary, ontology, and knowledge base become accessible at runtime. Uniquely, it can query over inferred graphs, not just asserted data.
NLP Pipelines - Named Entity Recognition, entity linking, relation extraction: pipelines that extract entities, relationships, and events from unstructured text and link them to the knowledge graph’s vocabulary and knowledge base. This is where the structured and unstructured worlds meet. NLP populates the knowledge base with formally typed, ontology-aligned assertions harvested from documents, reports, and communications.
Vector Databases - Stores for high-dimensional embeddings that support approximate nearest-neighbor search. They provide a complementary retrieval pattern - finding what is conceptually proximate in embedding space rather than what is formally true according to the ontology. Combined with the symbolic layer, vectors and ontology become two sides of the same retrieval coin.
Knowledge Graph Embeddings - Methods like RDF2Vec, TransE, RotatE, and ComplEx translate symbolic graph structure into numeric vector representations. They enable machine learning tasks that the symbolic layer alone cannot perform: link prediction, entity resolution, similarity search, and classification. The formal ontology gives them structure. The embeddings give them reach.
Graph Algorithms - Computational methods that operate over the graph’s network structure: finding paths between entities, identifying highly connected nodes, detecting clusters, and comparing datasets for consistency. They surface relationships hidden across the graph topology - the kind of structural insight that no query language can deliver.
Each of these components becomes dramatically more effective when it sits on top of a governed, formally modeled knowledge architecture. A reasoner without an ontology has nothing to reason about. A SHACL layer without defined schemas has nothing to validate. An NLP pipeline without a controlled vocabulary has no target to link against. The optional components are optional in the architecture - but the architecture is what makes them work.
The Architecture Question
The tool question - Neo4j or GraphDB or Stardog - is a deployment decision. It matters, but it comes last.
The architecture question is the one that determines whether your knowledge graph can actually do what a knowledge graph is supposed to do: encode not just data, but meaning.
Do you have the vocabulary? The taxonomy? The thesaurus? The ontology? The knowledge base? The metadata schemas? The governance?
Building a controlled vocabulary forces you to define your terms. Building a taxonomy forces you to classify your concepts. Building a thesaurus forces you to resolve ambiguity. Building an ontology forces you to formalize the logic of your domain. Each stage of the Ontology Pipeline extracts and encodes tacit organizational knowledge into structures that machines can reason over.
The tool is the container. The architecture is what goes into it. And that architecture - fully realized, with its vocabulary, ontology, knowledge base, metadata, validation, reasoning, and query layers - becomes the mechanism through which your organization’s unique advantage is made computationally accessible.
Without it, AI systems operate on generic knowledge that any competitor’s AI can replicate. With it, they’re grounded in the specific, formally structured, provenance-tracked knowledge that defines what makes you different.
Start with the architecture. The tools will follow.
Sources:
Juha Korpela and Säde Haveri, Helsinki Data Mafia Podcast, “Towards HDW2026!” (March 19, 2026);
Jessica Talisman, “Knowledge Graphs, Part I, Architecture, Components and a Landscape of Patterns” (2026);
Jessica Talisman, “The Ontology Pipeline - A Semantic Knowledge Management Framework” (2025);
Knowledge Graph Academy, Module 6: “AI Agents, LLMs, and Knowledge Graphs” (2026).
Hi @Josef 'Jeff' Heusserer I am new to the graphing community, and I really enjoyed your text, and I am sure it will be a great time in Helsinki. I have two general questions; maybe you can help me better understand.
In an organization, let's just take an easy word like “customer”, has different meanings, represents different people, and leads to other kinds of conversations depending on if you speak to sales, support, or product management. How does this map to your controlled vocabulary or the other phases?
The second question is about temporality. In an organization, development is speaking and thinking about goals and making decisions related to work in two week sprint intervals; middle management are thinking about goals and making decisions based on internvals of 3-6 months and Executives 1—5 years. How does your framework understand temporality, and is it able to understand the different roles and support them in their contexts?
Thanks so much
Thank you and welcome! Will be great to see you IRL in Helsinki! ❤️