The Integrated Framework at a Glance
A Four-Phase (3+1) Approach to Metadata Management That Actually Delivers Business Value


I’ve recently read three books:
Fundamentals of Metadata Management (in short Meta Grid) by Ole Olesen-Bagneux (Ole Olesen-Bagneux)
Halo Data - A New Methodology to Leverage the Value in your Data written by Caroline Carruthers And Peter Jackson
Data Quality ROI - A Playbook for Business-Driven Data Quality from Gaurav Patole (Gaurav Patole)
This is Part #3 in the series The Holy Trinity for Enterprise Data Foundations. The series explores how these three essential books work together as a unified framework for building your enterprise data foundation.
A Note on Validation
Because this article represents the heart of the entire series - synthesizing three distinct methodologies into a unified framework - I wanted to ensure I had understood each author’s intent correctly. I reached out to all three authors for their feedback before publication. I’m grateful that Caroline Carruthers, Gaurav Patole, and Ole Olesen-Bagneux each took the time to review the integrated framework and share their perspectives. Their input has been incorporated where needed. Any remaining errors or misinterpretations are, of course, my own. Thank you, Caroline, Gaurav, and Ole, for your generosity and for writing books that genuinely move our field forward.
Introduction
Most organizations treat metadata management as a technical project rather than a strategic capability. They acquire catalogs, deploy lineage tools, and staff governance committees - yet five years later, the same complaints persist: “We don’t know what data we have.” “Nobody trusts the numbers.” “The business ignores our governance policies.”
The problem is not missing technology. The problem is that metadata work rarely connects to business outcomes. Technical teams document data assets in isolation. Business teams define requirements without understanding what already exists. Governance functions enforce policies without measuring value. The result is effort without impact.
In my previous articles, I introduced three books that address this challenge from complementary angles:
Data Quality ROI tackles the human and organizational side - business engagement, ROI justification, and cultural change
Halo Data provides a formal framework for understanding and measuring data value through metadata
Meta Grid addresses the architectural reality of coordinating multiple overlapping metadata repositories
In The Holy Trinity for Enterprise Data Foundations, I explained why these three books together form a complete answer to the central challenge of modern data management. In The Physics of Enterprise Data, I explored how each book uses physics metaphors - Newton’s Laws, Atomic Theory, and Nuclear Fusion - to explain data behavior. In The Vocabulary of Data Value, I mapped how terminology aligns and diverges across the three frameworks.
This article synthesizes those insights into a single, actionable framework: the Integrated Metadata Management Framework for Business Value.
The core logic is simple:
Discover → Value → Activate → Coordinate
You cannot value what you have not discovered. You cannot activate what you have not prioritized. You cannot sustain without coordination.
This article provides the complete mental map. Subsequent articles will dive deep into each phase with detailed playbooks, deliverables, and implementation guidance.
The Sequential Value Chain
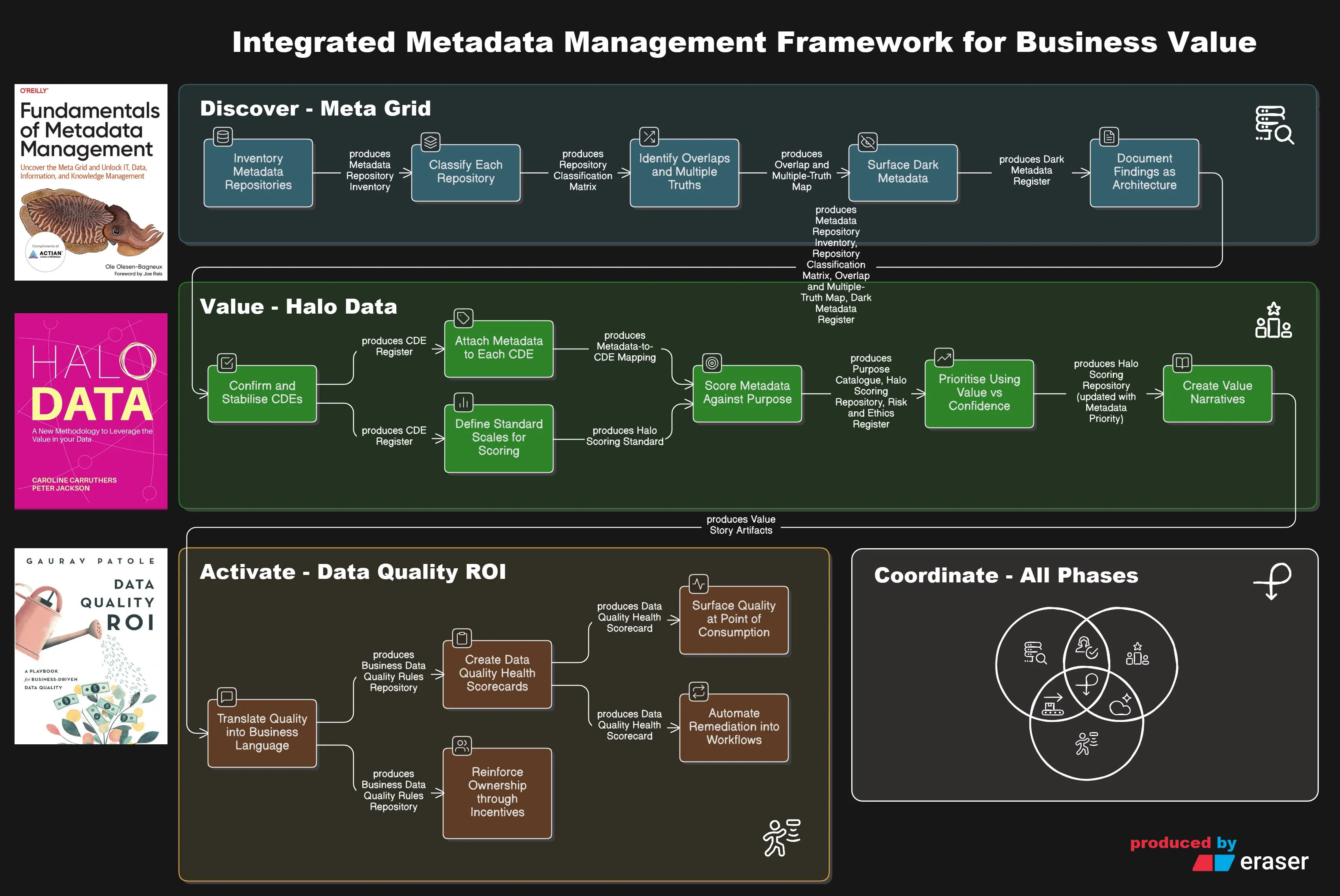
The framework operates as a sequential value chain where each phase builds on the previous one. The order matters because each phase produces outputs that the next phase requires as inputs.
Phase 1 – Discover (from Meta Grid) answers: What metadata do we have and where does it live?
You map existing repositories, classify them, surface overlaps and contradictions, and document dark metadata that lives in scripts and spreadsheets. Without discovery, you are building on sand.
Phase 2 – Value (from Halo Data) answers: Which metadata creates the most business value?
You identify Critical Data Elements, attach metadata to them, score each element for value, potential, and confidence, and prioritize based on purpose. Without valuation, every data asset looks equally important - which means nothing gets prioritized.
Phase 3 – Activate (from Data Quality ROI) answers: How do we surface quality signals where people work?
You translate quality into business language, embed trust indicators in operational tools, automate remediation workflows, and reinforce ownership through incentives. Without activation, your metadata stays in catalogs that nobody visits.
Phase 4 – Coordinate (All Books) is not a sequential phase but an ongoing operating system. It maintains alignment over time by repeating discovery, valuation, and activation tasks as the landscape changes.
Each book contributes primarily to specific phases:
Meta Grid provides the methodology for Discover and the architectural patterns for Coordinate
Halo Data provides the valuation framework for Value and the re-scoring logic for Coordinate
Data Quality ROI provides the activation playbook for Activate and the governance model for Coordinate
No single book covers the complete value chain. Together, they form a unified approach.
Four-Phase Overview

Tasks and Deliverables at a Glance
Each phase consists of sequential Tasks that produce specific Operating Deliverables. Here is the complete task inventory across all phases.
Operating Deliverables are the artifacts that make each phase tangible. They are not documentation for its own sake - they are activation surfaces that exist to change behavior.
Each Operating Deliverable contains multiple Core Components - the conceptual building blocks that encode intent, ownership, and action. Detailed specifications for each deliverable will be covered in a future Article of this series.
Phase 1 – Discover

The Discover phase makes the unconscious explicit. It creates visibility into an otherwise fragmented metadata landscape without attempting to fix or standardize anything yet.
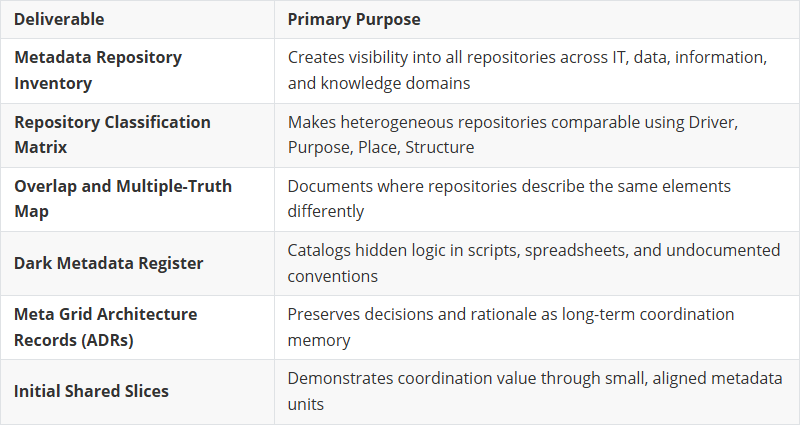
Task 1: Inventory Metadata Repositories
Identify all metadata repositories across IT, data, information, and knowledge management domains - including tools, spreadsheets, scripts, wikis, and databases. The goal is a raw inventory of what exists, not a judgment of quality.
Task 2: Classify Each Repository
Apply a consistent classification scheme to each repository: Driver (innovation, operations, regulation), Purpose (decisions/actions supported), Place (where it lives), and Structure (metamodel). This makes heterogeneous repositories comparable without forcing harmonization.
Task 3: Identify Overlaps and Multiple Truths
Surface where multiple repositories describe the same real-world elements differently. Document shared objects (applications, datasets, processes) and their repository-specific representations. Treat inconsistency as structural reality, not as data quality failure.
Task 4: Surface Dark Metadata
Reveal metadata hidden in scripts, ETL jobs, spreadsheets, and naming conventions. Interview practitioners about “how things really work.” Dark metadata often contains critical business logic that never enters formal repositories.
Task 5: Document Findings as Architecture, Not Reports
Capture decisions and observations as Architectural Decision Records (ADRs). Use simple lists, diagrams, and tables. Avoid dashboards and maturity models. The goal is durable documentation that supports coordination over time.
Phase 1 - Operating Deliverables
Phase 2 – Value

The Value phase turns discovered metadata into prioritized investments. It establishes what matters most and creates a shared language for discussing data value across the organization.
Task 1: Confirm and Stabilize CDEs
Establish a small, stable set of Critical Data Elements that anchor all value and governance decisions. CDEs are business entities that directly affect outcomes, risk, or regulation - examples include Customer, Product, Policy, Asset.
Task 2: Attach Metadata to Each CDE
Link datasets and metadata elements to the CDEs they describe or enrich. This creates the “Halo” around each nucleus. Metadata without a CDE connection should be flagged for review.
Task 3: Define Standard Scales for Scoring
Standardize scales for Halo dimensions (n, v, p, c, Rp, Rv, e) across the organization. Agreement on scoring semantics is required to make comparisons meaningful and enable portfolio-level prioritization.
Task 4: Score Metadata Against Purpose
Assign scores for each metadata element in the context of specific business purposes. The same metadata may have different scores for different purposes - this is the “quantum behavior” of data value.
Task 5: Prioritize Using Value vs. Confidence
Compare metadata using potential (p) versus confidence (c), not potential alone. High p with low c indicates long-term opportunity. Moderate p with high c indicates near-term activation. This guides sequencing and investment.
Task 6: Create Value Narratives
Translate Halo scores into clear, decision-ready stories that justify action and funding. Value narratives are how technical valuation becomes executive communication.
Phase 2 - Operating Deliverables

Phase 3 – Activate

The Activate phase embeds quality signals into daily work. It turns metadata from documentation into behavioral drivers that change how people create, consume, and trust data.
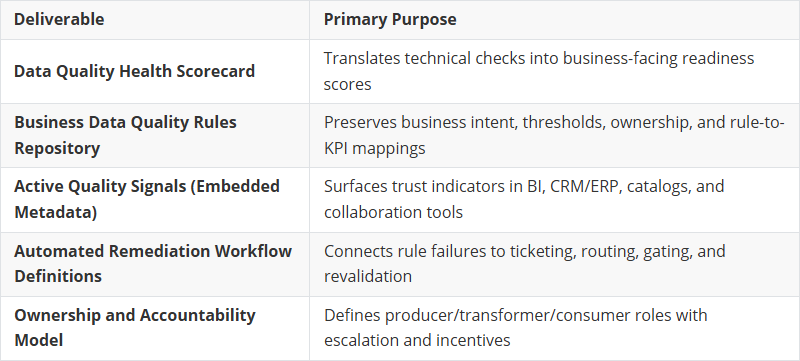
Task 1: Translate Quality into Business Language
Turn technical data defects into decision-focused signals that each business group understands. Explicitly separate technical DQ rules from business DQ rules. Keep technical checks for pipeline stability and diagnostics, but translate business rules into outcome-oriented language tied to decisions, risks, and KPIs. Make the cost of inaction explicit so business leaders see why quality matters to what they own. Map supporting technical checks to these business rules only where they enable a concrete business outcome. Run focused sessions with business owners to validate language, thresholds, and real-world impact.
Task 2: Create Data Quality Health Scorecards
Compress many checks into a small set of business-facing readiness scores. Group rules into 4–6 business dimensions, weight by decision impact, and publish on a fixed cadence with visible history.
Task 3: Surface Quality at the Point of Consumption
Make trust signals available inside the tools where users already consume data - dashboards, CRM/ERP screens, catalogs, collaboration tools. Add lightweight trust badges with one-click drill-down to details.
Task 4: Automate Remediation into Workflows
Define fail conditions that trigger workflow actions. Auto-create and route tasks to producing teams. Where feasible, enforce “cannot proceed” gates until required validations are satisfied. Close the loop: fix applied → revalidation → score updated.
Task 5: Reinforce Ownership Through Incentives
Define performance measures that connect DQ improvements to business outcomes. Implement rewards that matter to teams. Publicize wins and progress. Clarify roles across producers, transformers, and consumers.
Phase 3 - Operating Deliverables
The Role Model
All phases share a common role structure that enables consistent RACI assignments. Rather than defining dozens of specialized roles, the framework consolidates into four aggregate roles that carry through every task.
Business/Product Owners
Executives, sponsors, and domain owners who define what “good enough” means, own business rules and thresholds, and are accountable for outcomes. They assign realized value (v) and potential value (p) in Halo scoring.
Data Owners / Engineers
Teams responsible for data creation, transformation, and technical implementation. They own repositories, implement checks and integrations, and assign confidence scores (c). This includes EAM teams, ITSM teams, data catalog owners, and data engineering functions.
Risk / Privacy / DPO
Functions responsible for privacy, security, compliance, and ethics. They own ISMS, DPR, and RIMS repositories. They assign Rp (privacy risk), Rv (business risk), and e (ethical risk) scores and must be consulted on classification, retention, and processing records.
Cross-functional Team
The enabling team that coordinates across phases. This role integrates:
Data Discovery Team (from Meta Grid): Reference-librarian-style coordinators who understand all repositories and broker shared structures
CDE Team (from Halo Data): Cross-functional group that confirms CDEs and governs valuation
Central Governance Core (from Data Quality ROI): Function providing standards, tooling, and coordination across domains
In practice, these may be the same people wearing different hats depending on which phase is active. The key insight is that coordination requires a dedicated enabling function - it does not happen through goodwill alone.
Detailed RACI matrices for every task and deliverable will be covered in a future Article about Roles, RACI & Team Topologies.
How Coordination Works
Coordination is the most misunderstood aspect of the framework. It is not a fourth sequential phase that happens after Activate. It is an ongoing operating rhythm that runs continuously while other phases execute.
The “Never Finalized” Principle
Meta Grid explicitly states that the meta grid is “never finished; it evolves.” This is not a failure mode - it is a design principle. Repositories change. New tools appear. Dark metadata re-emerges. CDEs evolve as business strategy shifts. What was “good enough” last quarter may be inadequate today.
Coordination accepts this reality and builds repetition into the operating model.
Five Coordination Capabilities
Each task in the framework creates a specific coordination capability when repeated over time:
1. Semantic Alignment
CDEs act as long-term semantic anchors. Re-confirming CDEs periodically ensures all teams still align on what really matters. This prevents divergent definitions across domains.
2. Cross-Repository Coherence
Metadata-to-CDE mapping forces teams to declare relevance and expose dependencies. Periodic reassessment prevents fragmentation as repositories evolve independently.
3. Comparability Across Teams
Standard scoring scales create a shared measurement system. Without periodic calibration, scoring drifts and portfolio-level prioritization becomes meaningless.
4. Intent Alignment
Scoring against explicit purpose prevents silent reuse of metadata. Purpose catalogues must be reviewed as new use cases emerge - especially AI/ML applications that combine data in novel ways.
5. Portfolio-Level Decision Alignment
Prioritization decisions must be revisited as confidence changes, new data sources appear, or business priorities shift. A quarterly coordination rhythm is typical.
The Coordination Loop
In practice, coordination means:
Repeating Discover tasks to detect landscape changes (new repositories, shadow tools, platform-specific meta grids)
Repeating Value tasks to re-score as context evolves (new purposes, changed risk profiles, proven value)
Repeating Activate tasks to maintain embedded signals and workflows (new dashboards, changed BI tools, evolved CRM/ERP screens)
The Cross-functional Team operates as the coordination heartbeat. Without this dedicated enabling function, coordination degenerates into ad-hoc reactions to problems.
Practical Takeaways
1. Entry Point Flexibility
Start where your pain is greatest:
Fragmented repositories, no visibility? Start with Discover
No shared language for data value? Start with Value (define CDEs, establish scoring)
Stalled initiatives, business disengagement? Start with Activate (sponsorship, alignment, accountability)
The sequence is still required - but you can emphasize one phase while laying groundwork for others. An organization drowning in undocumented metadata cannot meaningfully score value. An organization with clear CDEs but zero business engagement cannot activate without first fixing sponsorship.
2. All Phases Required
Skipping phases creates gaps that undermine results:
Discover without Value = You know what you have, but you invest equally in everything
Value without Discover = You score what you see, but miss the dark metadata that actually runs the business
Activate without Value = You embed signals, but cannot prioritize which signals matter most
Any phase without Coordinate = Your work decays as the landscape changes around it
3. Deliverables Are Activation Surfaces
Every Operating Deliverable exists to change behavior, not to document for documentation’s sake. The Data Quality Health Scorecard is not a report - it is the primary activation interface. The Halo Scoring Repository is not a database - it is the decision backbone that drives prioritization.
If an artifact does not change behavior, question whether it should exist.
4. Humans Before Machines
The foundational insight across all three books: The metadata foundation must be established by humans. AI accelerates after the foundation exists.
What only humans can do:
Align on purpose and definitions across functions with competing perspectives
Design governance architecture: ownership, accountability, decision rights
Determine what matters: value and relevance are context-dependent judgments
Drive behavioral change: moving from inaction to action is a human journey
Coordinate across repositories: navigating overlapping worldviews requires negotiation
Where AI helps - after foundations exist:
Anomaly detection in metadata quality
Rule suggestions based on patterns
Mapping proposals between repositories
Conversational search over the meta grid
The sequence is non-negotiable: Humans establish → AI accelerates → Humans validate.
What Comes Next
This article provides the complete mental map. The following articles in this series will dive deep into each component:
Phase 1 – Discover
A detailed walkthrough of the five Discover tasks, including prerequisites, task-by-task guidance, and complete specifications for all six deliverables. Grounded in Meta Grid methodology.
Phase 2 – Value
A detailed walkthrough of the six Value tasks, including the Halo scoring model, CDE governance, and specifications for all seven deliverables. Grounded in Halo Data methodology.
Phase 3 – Activate
A detailed walkthrough of the five Activate tasks, including business translation patterns, embedded metadata implementations, and specifications for all five deliverables. Grounded in Data Quality ROI methodology.
Coordination – The Operating System
How coordination works across all phases, the five coordination capabilities in detail, cadence design, and failure modes when coordination breaks down.
Roles, RACI & Team Topologies
Complete RACI matrices for all 16 tasks and 18 deliverables. How to integrate the Data Discovery Team, CDE Team, and Central Governance Core into a unified cross-functional function.
Operating Deliverables Deep Dive
Detailed specifications for all 18 deliverables, including Core Components, artifact templates, and integration patterns between deliverables.
Implementation Roadmap
How to sequence framework adoption based on organizational maturity, pain points, and available resources. Includes starter templates and first-90-days guidance.
Conclusion
The Integrated Metadata Management Framework transforms metadata from technical overhead into business value. It does this by following a simple but rigorous logic:
Discover what exists - including the dark metadata no one talks about
Value what matters - using a standardized scoring model that creates shared language
Activate where decisions happen - embedding signals into daily workflows
Coordinate continuously - because the landscape never stops changing
Three books. Four phases. Sixteen tasks. Eighteen deliverables. Four roles.
This is the complete architecture. The subsequent articles will show you how to build it.
If you want to support my work, here are the best ways…
✦ Share this post to your team (it’s free).
✦ Like and comment.
What resonates here is the insistence that metadata only matters when it changes human behavior, not when it’s perfectly documented. This framework respects the emotional and organizational reality: people don’t ignore data foundations because they’re lazy, but because value, ownership, and purpose were never made visible where decisions happen.
I really think you are onto something here. I like the framework, maybe it is a bit convoluted, but the core ideas are simple: discover, value, activate, and coordinate. I would not see this as depending only on metadata. Traditional data hubs and stores should follow similar patterns as well.